

<안내>
필자도 배우는 입장이라 틀린점, 잘못된 점이 있을 수 있습니다.
그러니 지적, 피드백 환영합니다.
Mission : It's Your Turn!¶
1. 본문에서 언급된 Feature를 제외하고 유의미한 Feature를 1개 이상 찾아봅시다.¶
- with Survived
- Hint : Fare? Sibsp? Parch?
2. Kaggle에서 Dataset을 찾고, 이 Dataset에서 유의미한 Feature를 3개 이상 찾고 이를 시각화해봅시다.¶
함께 보면 좋은 라이브러리 document
무대뽀로 하기 힘들다면? 다음 Hint와 함께 시도해봅시다:¶
- 데이터를 톺아봅시다.
- 각 데이터는 어떤 자료형을 가지고 있나요?
- 데이터에 결측치는 없나요? -> 있다면 이를 어떻게 메꿔줄까요?
- 데이터의 자료형을 바꿔줄 필요가 있나요? -> 범주형의 One-hot encoding
- 데이터에 대한 가설을 세워봅시다.
- 가설은 개인의 경험에 의해서 도출되어도 상관이 없습니다.
- 가설은 명확할 수록 좋습니다 ex) Titanic Data에서 Survival 여부와 성별에는 상관관계가 있다!
- 가설을 검증하기 위한 증거를 찾아봅시다.
- 이 증거는 한 눈에 보이지 않을 수 있습니다. 우리가 다룬 여러 Technique를 써줘야합니다.
.groupby()를 통해서 그룹화된 정보에 통계량을 도입하면 어떨까요?.merge()를 통해서 두개 이상의 dataFrame을 합치면 어떨까요?- 시각화를 통해 일목요연하게 보여주면 더욱 좋겠죠?
In [3]:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
In [4]:
titanic_df = pd.read_csv("./train.csv")
MISSION 1¶
- 유의미한 Feature 찾기
In [6]:
titanic_df[['Fare','SibSp','Parch']]
Out[6]:
| Fare | SibSp | Parch | |
|---|---|---|---|
| 0 | 7.2500 | 1 | 0 |
| 1 | 71.2833 | 1 | 0 |
| 2 | 7.9250 | 0 | 0 |
| 3 | 53.1000 | 1 | 0 |
| 4 | 8.0500 | 0 | 0 |
| ... | ... | ... | ... |
| 886 | 13.0000 | 0 | 0 |
| 887 | 30.0000 | 0 | 0 |
| 888 | 23.4500 | 1 | 2 |
| 889 | 30.0000 | 0 | 0 |
| 890 | 7.7500 | 0 | 0 |
891 rows × 3 columns
가설 1 . Fare with Survived¶
In [7]:
fig, ax = plt.subplots(1,1,figsize=(5,5))
sns.kdeplot(x =titanic_df[titanic_df.Survived ==1]['Fare'], ax = ax )
sns.kdeplot(x =titanic_df[titanic_df.Survived ==0]['Fare'], ax = ax )
plt.legend(['Survived','Dead'])
plt.show()

In [49]:
x = np.arange(0,300,10)
y = titanic_df[titanic_df.Survived ==1]['Fare'] # count말고 저 구간의 mean을 구하고 싶은데 어떻게 해야하지?
plt.hist(y, bins = x)
plt.show()

kdeplot을 살펴본 결과, Fare가 높을 수록, 죽은사람보다 산 사람이 많아지는 것 같다.
궁금한 점
- histogram에서는 일정 구간의 자료 개수를 세 주는 것 같은데, 일정 구간의 평균을 구할 수 있을까 ?
- 예를들어, Fare가 0~10인 승객의 Survive 비율을 histogram의 Y 축에 넣으려고 하면 어떻게 할 수 있을까, 그렇게 하면 자료의 판도가 확 바뀔 수도 있을 것 같은데
가설 2. Survive with SibSp¶
In [96]:
titanic_df[['SibSp','Survived']].groupby(['SibSp']).mean()
Out[96]:
| Survived | |
|---|---|
| SibSp | |
| 0 | 0.345395 |
| 1 | 0.535885 |
| 2 | 0.464286 |
| 3 | 0.250000 |
| 4 | 0.166667 |
| 5 | 0.000000 |
| 8 | 0.000000 |
sns.catplot(x= 'Pclass',y = 'SibSp',kind = 'point', data = titanic_df)
plt.show()
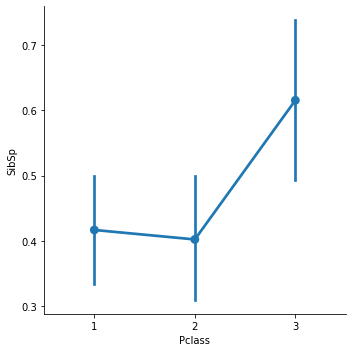
Pclass 1과 2에서는 평균 SibSp가 비슷했고, Pclass 3에서 SibSp가 증가했음을 볼 수 있다.
In [55]:
sns.catplot(x= 'SibSp',y = 'Survived',kind = 'point', data = titanic_df)
plt.show()

In [57]:
sns.catplot(x= 'SibSp',y = 'Survived',hue = 'Pclass', kind = 'point', data = titanic_df)
plt.show()

통계적으로, 배우자나 형제가 1명이상인 경우에 더 많이 생존했음을 볼 수 있다.
또, Pclass별로도 배우자나 형제가 2명까지는 증가할수록 생존할 확률이 높아짐을 알 수 있다.
가설3. Survive with Parch¶
In [81]:
sns.catplot(x= 'Parch',y = 'Survived',kind = 'point', data = titanic_df)
plt.show()

In [83]:
sns.catplot(x= 'Parch',y = 'Survived',hue = 'Pclass', kind = 'point', data = titanic_df)
plt.show()

Parent, children의 수 역시 늘어날 수록 생존률은 높아지는 것을 볼 수 있었다.
그러나 전체 Parch와 Survive의 관계를 보면 4명부터는 급격하게 떨어지는 것을 볼 수 있었는데, 이는 4명이상의 표본은 Pclass 3 에서만 발견되는 자료의 특수성에 기인한 것으로 보인다.
'TIL > [겨울방학 부트캠프]TIL' 카테고리의 다른 글
| TIL 13일 (22.01.18) (0) | 2022.01.18 |
|---|---|
| TIL 12일차 (22.01.17) (0) | 2022.01.18 |
| TIL 10일차 (22.01.14) (0) | 2022.01.15 |
| TIL 9일차 (22.01.13) (0) | 2022.01.14 |
| TIL 8일차 (22.01.12) (0) | 2022.01.13 |